Dota 2 Drafting Part 1: Data Collection
Dota 2 captain’s mode entails a drafting phase where a sequence of picks and bans are issued by the team captains. As of this writing, there have been 1,933,725,512 total matches of Dota 2 played, in all modes. It may be possible now with this body of data to build a machine learning algorithm for prediction and for drafting suggestions.
Getting the data
The web API for Dota 2 has two functions we can use to grab match data as a JSON object from some index. The first, GetMatchHistory, has a game mode argument and date argument which would make it ideal for stratifying the data by patch release. However, it has three flaws that preclude its use:
- It is capped (for some reason, most likely a bug judging from all the angry dev forum posts) at grabbing the most recent 500 games.
- It does not return the pick/ban record, only the game type of a match.
- The game mode argument currently does not work (lol Valve).
The second function, GetMatchHistoryBySequenceNum, does return the pick/ban record and does not have any limitation on how far it can reach, but it does not support any date parameters. Thus, determining the actual patch number a match was played in will necessitate going into the records and accessing the UNIX time that the match was played at. The other complication GetMatchHistoryBySequenceNum has is that the sequence numbers do not directly map to the order in which matches were played- I suspect that the sequence number is issued to a match once it has finished being indexed and processed into the Dota 2 database. In other words, it is no guarantee if the sequence number for match A is higher than the sequence number for match B that match A was played after match B.
The typical output from the GetMatchHistoryBySequenceNum call (for a captain’s mode match) looks like this:
{
"result": {
"status": 1, // success code
"matches": [
{
"players": [
{
// omitted: player ids and statistics such as gold earned
}
]
,
"radiant_win": true,
"duration": 2333, // our metric for how hard a team won the game
"start_time": 1447002472,
"match_id": 1923658257,
"match_seq_num": 1700000293,
// omitted: other game data not relevant to us
"picks_bans": [
{
"is_pick": false,
"hero_id": 75,
"team": 1, // 0: radiant, 1: dire
"order": 0
},
{
"is_pick": false,
"hero_id": 85,
"team": 0,
"order": 1
},
// etc. for the rest of the pick/ban records
]
}
// ... and so on for 99 more matches
]
}
}Since we only want to index captain’s mode matches, it suffices to check if the picks_bans key exists, and parse the serialized JSON into a csv for future use if it is.
Basic observation: Hero popularity
One simple question we can address right now is popularity: which heroes are the most frequently banned or picked? Even better, the ordered nature of the records allows us to distinguish which heroes are frequent first bans or picks. There are two teams, each getting five picks and five bans in some sequence (i.e. there are ten picks and ten bans total per game). After trimming the column headings from the csv, a simple Hadoop MapReduce task accumulates the frequencies for all hero picks and bans by when they occur.
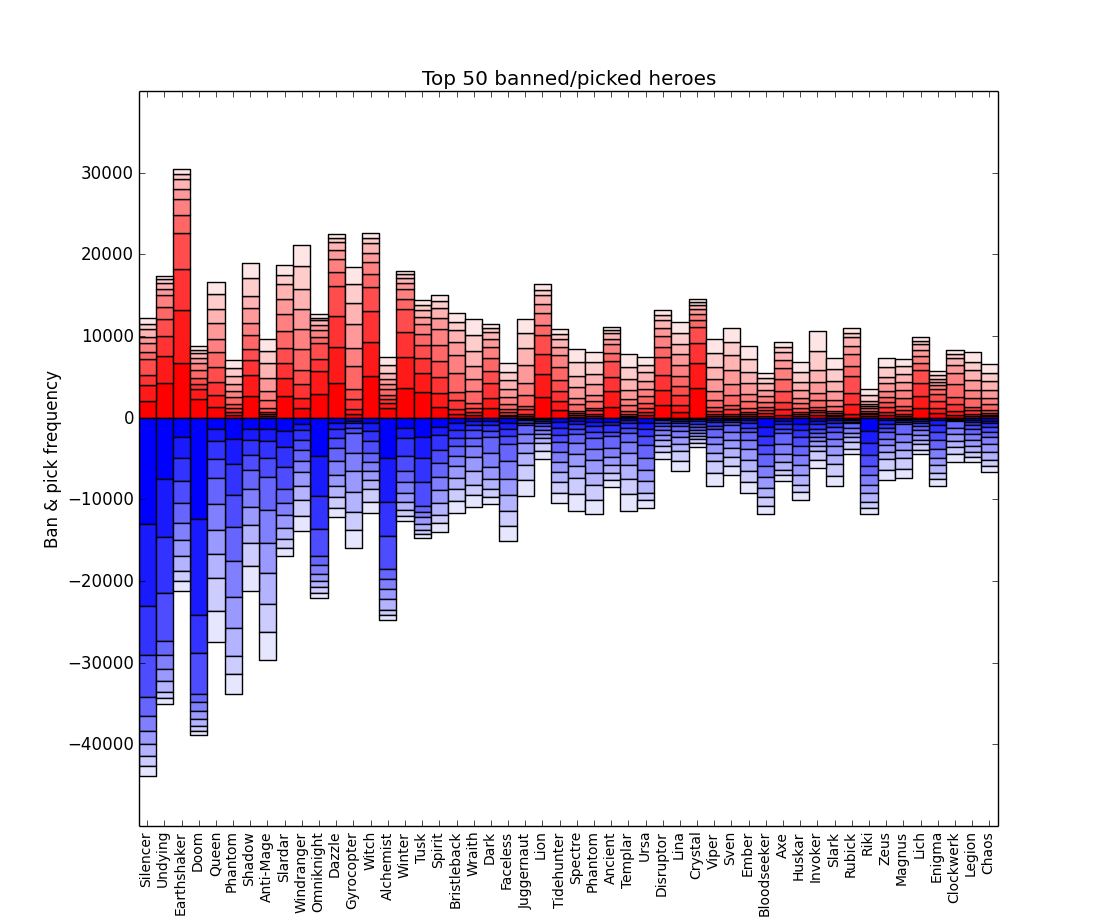
Parsing the MapReduce results into a pandas dataframe, I chose to graph the heroes that were most frequently banned/picked in total, with a stacked bar plot showing which phase the bans/picks come in on. This communicates which heroes are popular first picks or bans, i.e. heroes crucial to a team’s strategy succeeding (in the case of bans) or heroes that are particularly strong in the metagame (in the case of picks). Similarly, the timing of a pick or ban has implications; without diving too deep into the strategy of the game, hero drafting revolves around two primary goals:
- Identify an opponents strategy and curtail its effectiveness with the correct selection of one’s own picks and bans.
- Implementing your own strategy based on picks while limiting the opponent’s ability to address it with proper bans.
Of course, the strategy is much deeper and as of this writing still mostly unexplored space. Part of this project is to discern what features lead to a successful drafting phase.
Future plans
At this point, I have indexed 80 million Dota 2 matches, roughly 500,000 of which are captain’s mode matches. This is a sufficiently large data set to begin mining for insights; there are many possible directions we can go. Currently I have a cluster of Amazon EC2 instances with Hadoop setup and ready to go, and I’ll be poking around the data set for the more ‘obvious’ statistical features while I wait for more data points to accumulate.